連載 Magic V10リッチクライアント
第4回 Unicodeを用いたデータ定義
リッチクライアントはインターネットアプリケーションの一種です。インターネットアプリケーションである以上、様々なクライアント環境からアクセスされることを想定したアプリケーション作りが必要となります。使用する文字コードの選定においても、通常のWebページの作成時と同様、コード選択に配慮する必要があります。
丹田 昌信 (プロフィール)
インターネット上の文字化け問題
通常のクライアントサーバ型アプリケーションにおいては、Magic実行版が動作して日本語文字が正しく表示されれば、エンドユーザアプリケーション上で使用される文字コードの種類をとくに意識する必要はありませんでした。なぜならば、日本語版Magicが正常に動作すること自体で、そのパソコンに適切な文字セットがインストールされていて、それが正しく読み込まれていることが確認できたからです。
しかしながら、インターネットアプリケーションにおいては、たとえ日本語文字セットがインストールされていたとしても、どのコード体系を使用してページが構成されているかを明示的に宣言してやらない限り、正しく文字が表示されるとは限らないことが分かります。
たとえば、Webブラウザの使用においても、表示しようとしているWebページの文字コード宣言に対して、Webブラウザ側のエンコード設定が正しく行われていないと、そのページは文字表記の部分が正しく表示されない結果となります。
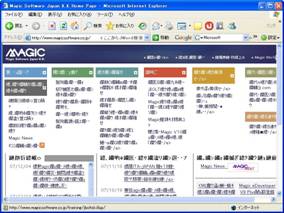
たとえば、Unicode(UTF-8)でコーディングされているMSJ社のWebサイトに対して、日本語Shift-JISでエンコーディングしようとすると、画面1のような表示になってしまい、文字化けを起こしてしまいます。
Windows XP Professional上にWebサーバをインストールするには、Windowsコントールパネルの「プログラムの追加と削除」で「Windowsコポーネントの追加と削除」を選択します。そして、「インターネットインフォメーションサービス(IIS)」をインストールします(画面1)。
- 画面 1 UTF-8のページをShift-JISでエンコードした場合の文字化け
また、文字コードの設定にまつわるもうひとつの問題点として、そのページに複数カ国にわたる言語を混在させようとした場合、それを構成する際のコード設定が適切でないと、Webブラウザ側のエンコード設定をどのように行ってもすべての言語を正しく表示させることができないことになります。
Webページの問題だけでしたら、多国語の混在はそれほど問題にならないかもしれませんが、エンドユーザアプリケーションのように、画面表示の大半がユーザデータで埋め尽くされるような環境にある場合、単一の言語コードの指定では他の言語が入力されただけで、その部分が文字化けを起こすといった結果になってしまいます。
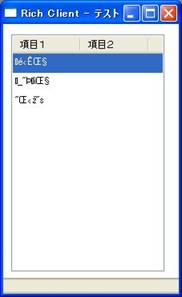
たとえば、英語圏やフランス語圏では通常、ラテン系のWindows ANSIコードが使用されており、この環境で作成されたリッチクライアントに日本語の文字を入力すると、画面2のように文字化けを引き起こしてしまいます。
- 画面 2 ANSI(Latin I)上での日本語の文字化け
仮に、このアプリケーションが日本語圏のクライアントを対象としないアプリケーションであったとしても、インターネット上で文字化けを起こすこと自体がアプリケーションの品質を問われる印象にも繋がりかねません。
これらのことを考慮すると、インターネットアプリケーションにおいて使用される文字セットの選択は、各国語の文字を同一テーブル上に混在させても文字化けを起こさないことを前提としたUnicodeの文字セットが推奨されることが分かります。
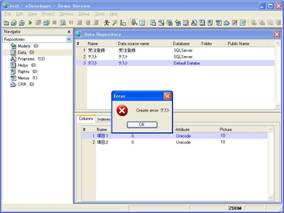
幸いMagic V10はUnicodeに完全対応しており、SQLServer 2005 ExpressもUnicodeに対応しています。ただし、Pervasive SQLの場合は、作成するファイルのバージョンに注意する必要があります。ファイルフォーマットが6.x以下の場合はエラーが出て、Unicodeでテーブルを作成することができません(画面3)。詳細は後述します。
- 画面 3 Pervasive SQLではファイルバージョンに注意

ここでは以上のようなことを考慮しながら、リッチクライアントアプリケーションを作成する前準備として、Unicodeを用いたデータソース定義の方法について解説してみたいと思います。
コードページの違いにおける文字化け
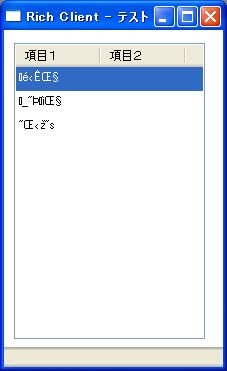
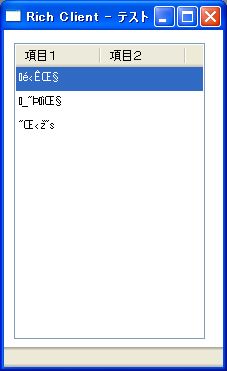
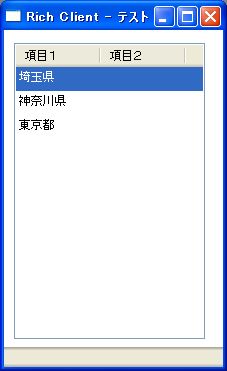
画面4は画面2と同じですが、Magic V10の英語版でデータソースを定義し、APGで作成したリッチクライアント上に日本語データを表示したときの例です。明らかに文字化けを引き起こしているのが分かります。
- 画面 4 英語版リッチクライアント上での文字化け

これは、Magic V10が英語版であるからなのではなく、Magicアプリケーションサーバ側の環境設定で日本語Shift-JISのコードページが指定されていないのが原因です。日本語コードページの指定は動作環境テーブルの「国別設定」→「外部コードページ」で行います(画面5)。
- 画面 5 日本語(Shift-JIS)コードページの指定
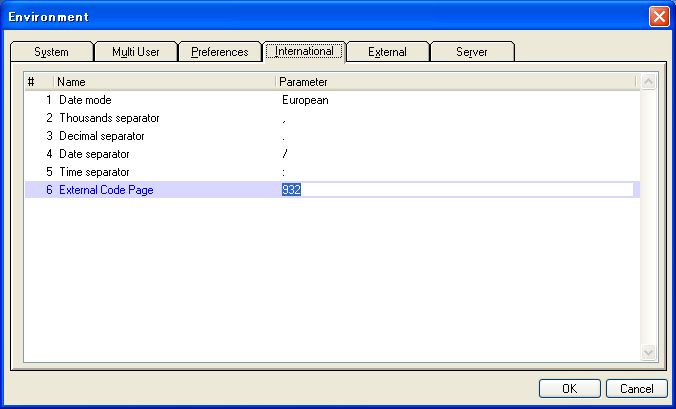
英語版Magicでは、ここの設定がデフォルトで「1252(Windows ANSI)」の設定になっています。「1252」は英語やフランス語等、ラテン系言語のコード体系を表していますので、ここを日本語Shift-JISのコードページ番号である「932」に変更してやれば、ひとまず画面4の文字化けは解消されることになります(画面6)。
- 画面 6 コードページの変更による文字化けの解消

つまり、この設定によってMagicアプリケーションサーバ側からリッチクライアント側に送られる文字セットのコード体系がANSI Shift-JISであるという旨の宣言がなされることになるわけです(*1)。
(*1)日本語版Magicでは、外部コードページの初期値は「932」になるものと思われます。
ちなみに、この外部コードページの設定はリッチクライアント以外に、ブラウザクライアント、COM、DLL、およびWebサービスのインタフェースにも適用されます。ここに何も指定しなかった場合は、使用しているWindowsサーバのデフォルトのコードページが使用されることになります。
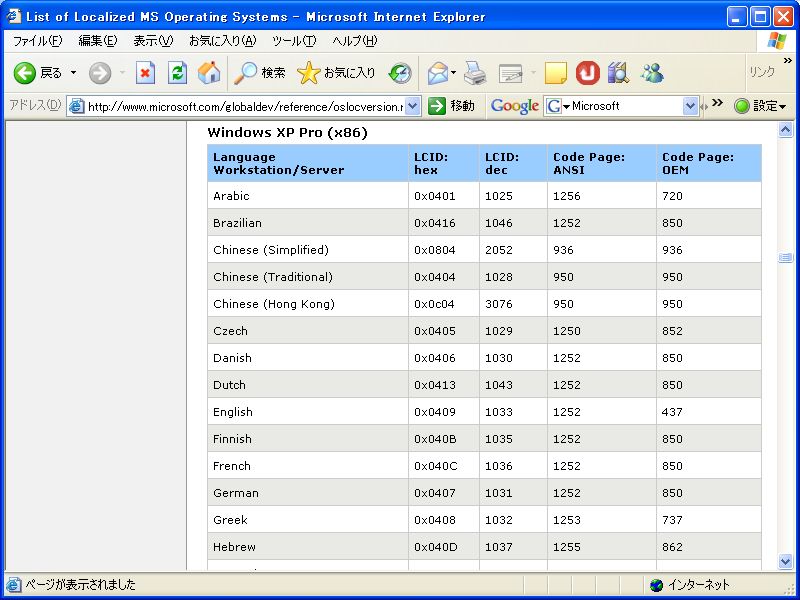
参考までに、各国語のコードページ一覧は下記のMicrosoftのWebサイトで参照することができます(画面7)。
■ http://www.microsoft.com/globaldev/reference/oslocversion.mspx
- 画面 7 Windowsがサポートするコードページ一覧
インターネット上で推奨されるUnicode
さて、これでShift-JISの文字データは正しく表示されるようになったわけなのですが、すでにお分かりのように、この設定では韓国語や中国語などが誤って、あるいは意図的に入力されたような場合に、これらの言語が文字化けを起こす結果となってしまいます。
冒頭でも述べたように、インターネットアプリケーションにおいては日本語圏以外からもアクセスがあり、それにともなって日本語以外のデータの入出力もあり得るということを考慮すると、アプリケーション上で文字化けを起こさせないという意味でも、より汎用的な文字セットであるUnicodeを使用することが望まれます。
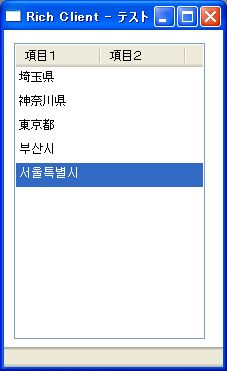
Unicodeはその誕生の理念からも分かるように、国際標準化をめざした文字コード体系で、世界の主要な言語のほとんどの文字がカバーされています。同じデータソース上に異なる言語の単語や文字列が混在しても、文字化けを起こすことなく正常に表示されます(画面8)。
- 画面 8 Unicodeで韓国語が混在しても文字化けしない

カラムにUnicodeを指定する
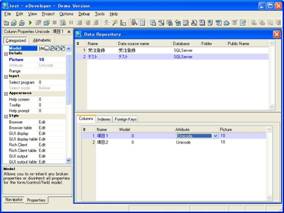
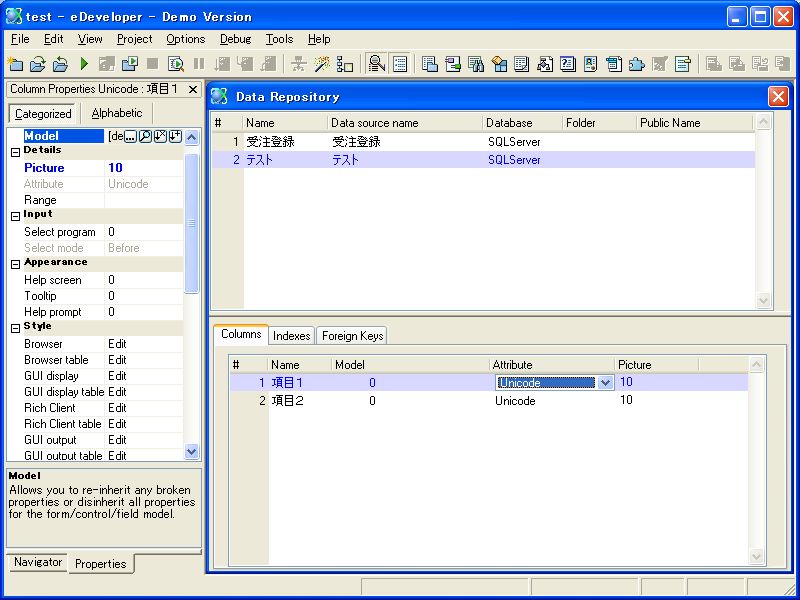
Magic V10のデータソースのカラムにUnicodeを指定するのはとても簡単です。カラムテーブルの「型」の欄に「U=Unicode」を指定するだけです。あとは、「A=文字」の場合と同じように書式等を設定します(画面9)。
- 画面 9 データソースでUnicodeを指定
これでAPGを起動すると、通常の文字型(A=ANSI)の場合と同じようにデータを入力したり表示したりできるようになります画面10。
- 画面 10 Unicodeの設定でAPGを起動
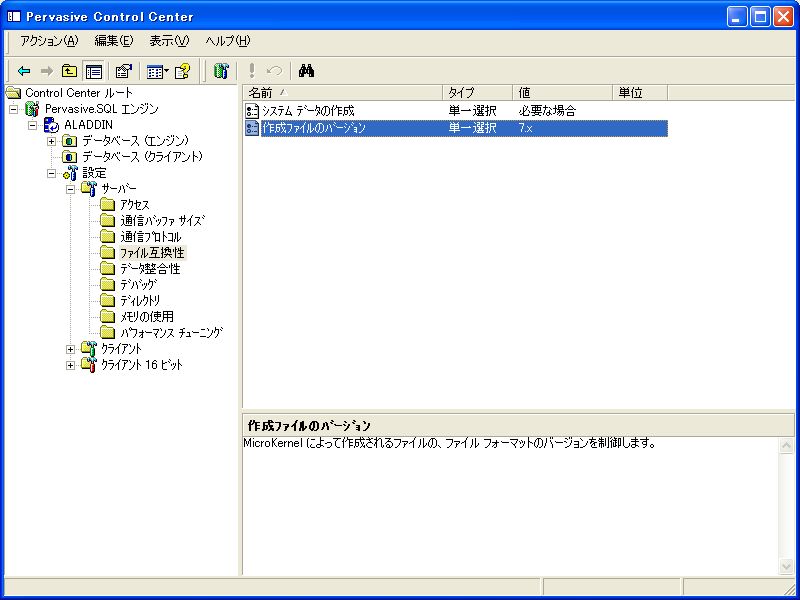
なお、前述のごとく、Pervasive SQLの場合はファイルバージョン7.x以降でUnicode対応となっていますので、Unicodeの指定でエラーが出る場合はPervasive Control Centerを起動して、ファイルフォーマットのバージョンを7.x以上にしておく必要があります(画面11)。この設定で、Pervasive.SQL V8でもUnicodeでテーブルが正常に作成されるようになります。
- 画面 11 Pervasiveではファイルバージョン7.x以上でUnicodeに対応
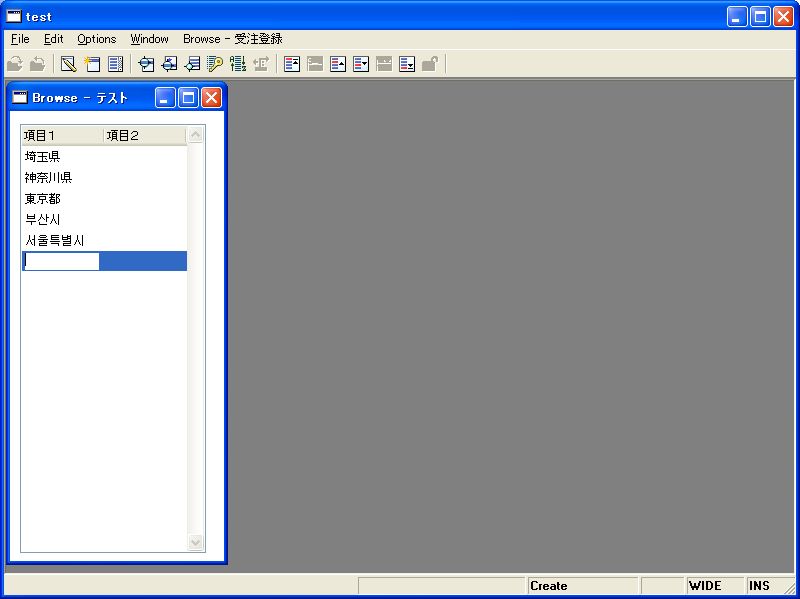
なお、APGで作成したリッチクライアントタスクも、これらのDBMSをバックエンドとしてUnicode文字の編集が正しく行えるようになります(画面12)。
- 画面 12 APGで作成したリッチクライアントタスク
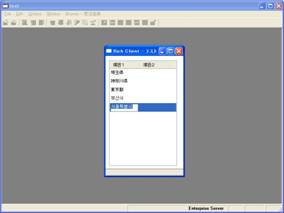

ちなみに、データソースにUnicodeを指定した場合は、Magicアプリケーションサーバ側の外部コードページの指定が何であっても、テーブルは文字化けを起こさずに正しく表示されます。
次回はいよいよ、「APGでリッチクライアントタスクを作成する」をお送りします。
(以上、2007年12月15日号)


