連載 Magic V10リッチクライアント
第8回 サブフォームを利用した受注入力タスクの作成(その2)
(第9回掲載時に、前後関係の問題からタイトルが変更されました。)
前号では、「U=Unicode」を用いた5つのデータソースの定義を行いました。ここでは、これらのデータソースに、外部テキストファイルのUnicodeデータを取り込む手順について学びます。
丹田 昌信 (プロフィール)
Unicode(UTF-8)のテキストファイル
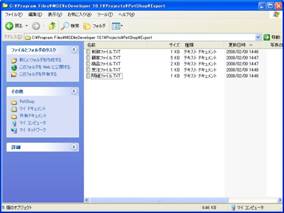
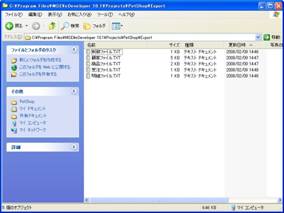
画面1は、前号で定義した制御ファイルから明細ファイルまでの5つのデータソースをMagic eDeveloper V10からAPGでテキスト出力したもののリストです。拡張子も「.TXT」となっていますので、これらが通常のテキストファイルであることがわかります。
- 画面 1 APGで出力したテキストファイル一覧
APGで出力していますので、各カラムは固定長の出力になっているはずです。
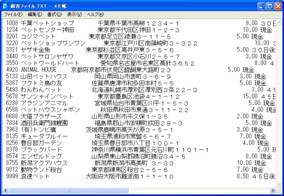
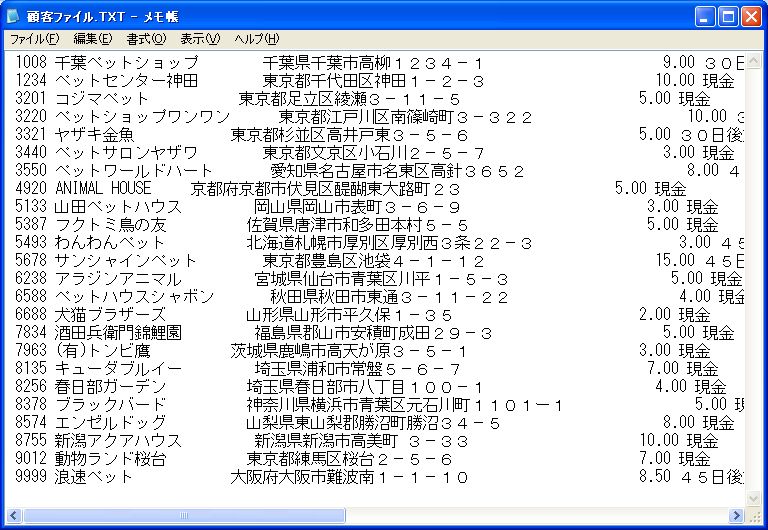
ところが、これらのテキストファイルをメモ帳などのテキストエディタで読み込むと、固定幅フォントを使用しているにもかかわらず、画面2のようにカラムの桁幅がそろっていないことがわかります。
- 画面 2 カラムの桁幅がそろわない
これは何故でしょうか。実は、Unicode(UTF-8)でエンコードされたデータは、個々の文字がアスキー文字であるか全角文字であるかにかかわらず、すべての文字を同じビット数の文字として取り扱うというUnicodeの理念に基づいているからです。
したがって、画面2の個々のカラムデータをスペース等も含めて手動で数えてみると、Magic側で定義した書式の桁数と合致していることがわかります。このあたりが従来の半角文字、全角文字を数える場合の計算方式と異なりますので、注意が必要です。
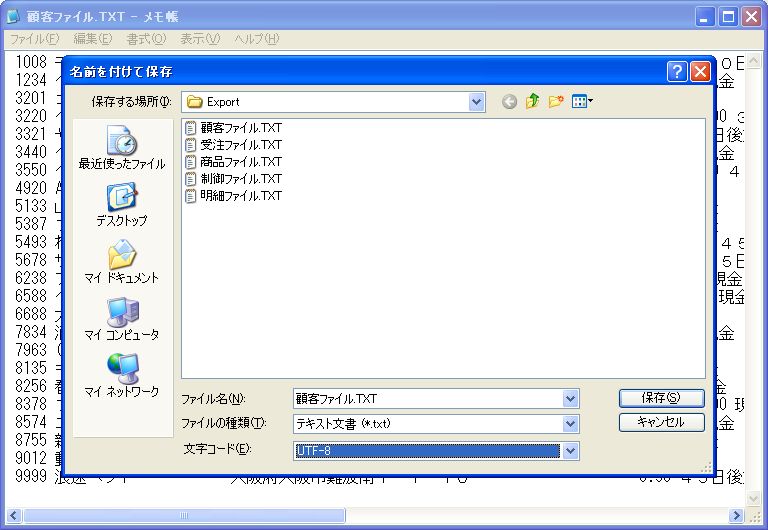
なお、画面2の状態でWindowsメモ帳の「名前を付けて保存」ダイアログを開くと、「文字コード」の欄が「UTF-8」になっていることが確認できます(画面3)。
- 画面 3 文字コード欄が「UTF-8」になっている
これにより、このテキストファイルが従来のANSI(Shift-JIS)で保存されたテキストファイルではないことがわかります(※1)。
※1Unicodeのカラムを含まないデータソースのテキスト出力は、デフォルトでは従来通りANSI(Shift-JIS)で出力されます。
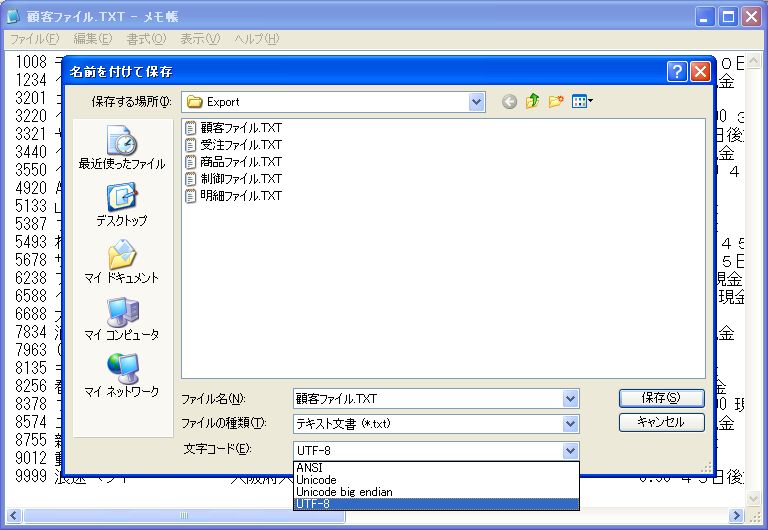
ちなみに、画面3の文字コード欄のドロップダウンメニューを開くと、「UTF-8」以外に「Unicode」、「Unicode big endian」という選択肢が表示されます。このことから、どうやらマイクロソフト社が提唱するところの「Unicode」とは、「UTF-16」の「little endian」であるらしいことが窺い知れます。したがって、「Unicode」という文字コード体系の名称と、「UTF-8」というエンコード方式の呼称がこのように並列の選択肢として並んでしまうという、分かりにくい表示となってしまっています(画面4)。
- 画面 4 文字コード欄の選択肢
それでは、これらの5つのUnicode(UTF-8)テキストファイルのデータをMagic側に取り込む作業を行ってみたいと思います。
はじめに、下記の書庫をダウンロードし、書庫内の5つのファイルをプロジェクトフォルダである「PetShop」フォルダの中の「Export」フォルダに解凍します。
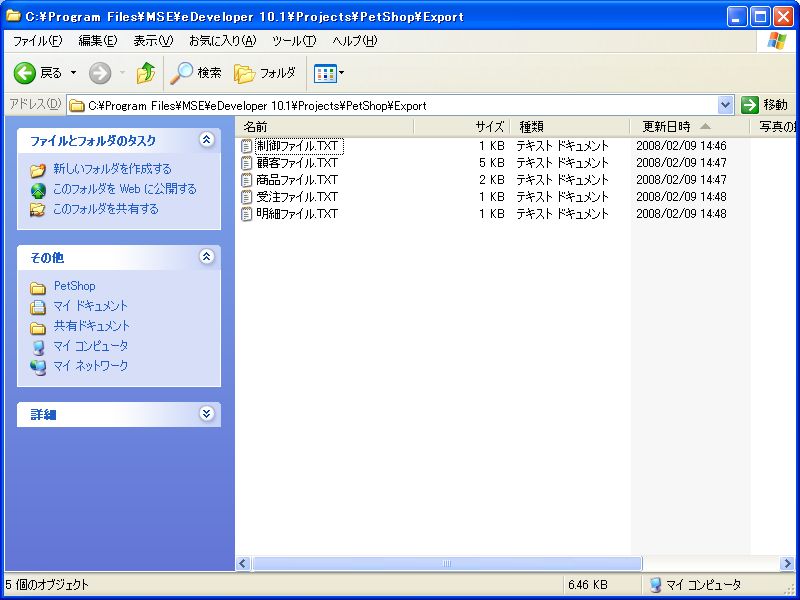
解凍が完了すると、画面5のようになります。
- 画面 5 Unicode(UTF-8)テキストファイルの解凍
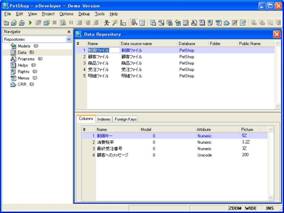
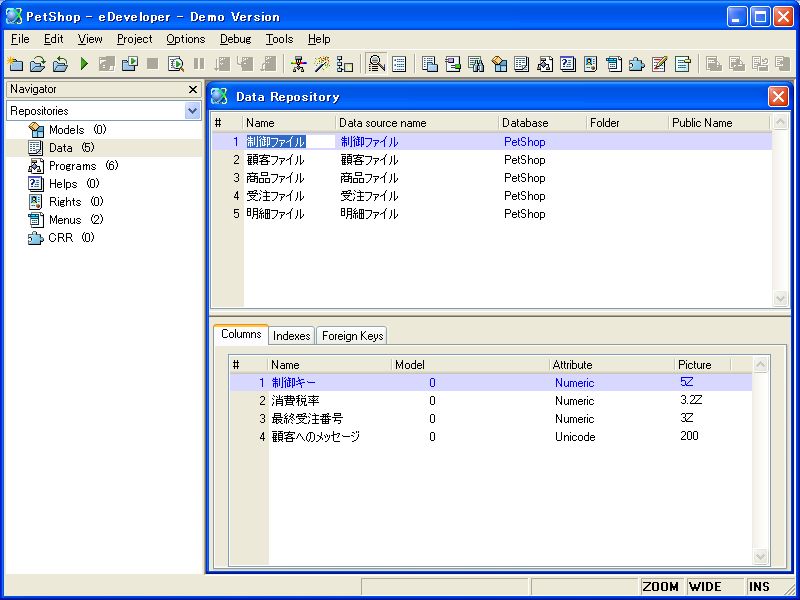
続いて、これらをMagicのAPG機能を用いてデータ入力します。PetShopプロジェクトを開き、データリポジトリの「制御ファイル」の行にカーソルを合わせます(画面6)。
- 画面 6 データリポジトリの制御ファイル
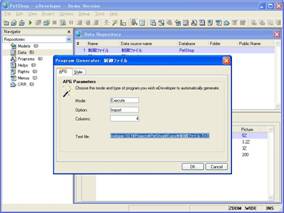
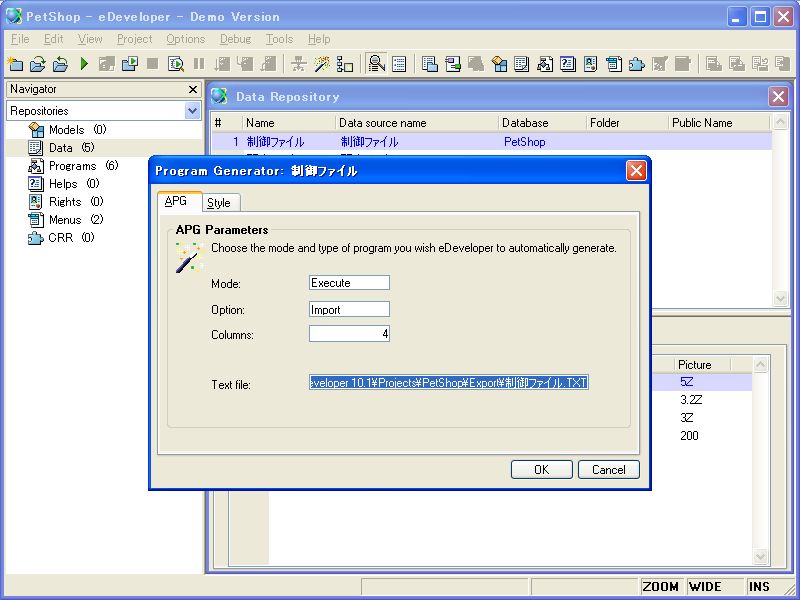
プルダウンメニューの「オプション」→「APG」でAPGを起動し、「モード」欄を「E=実行」、「オプション」欄を「I=入力」として、「テキストファイル」欄に、画面5で解凍した制御ファイル.TXTのパスを指定します(画面7)。
- 画面 7 制御ファイル.TXTのAPG入力
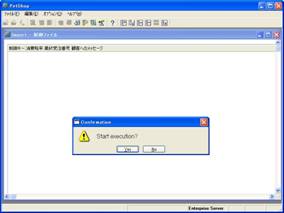
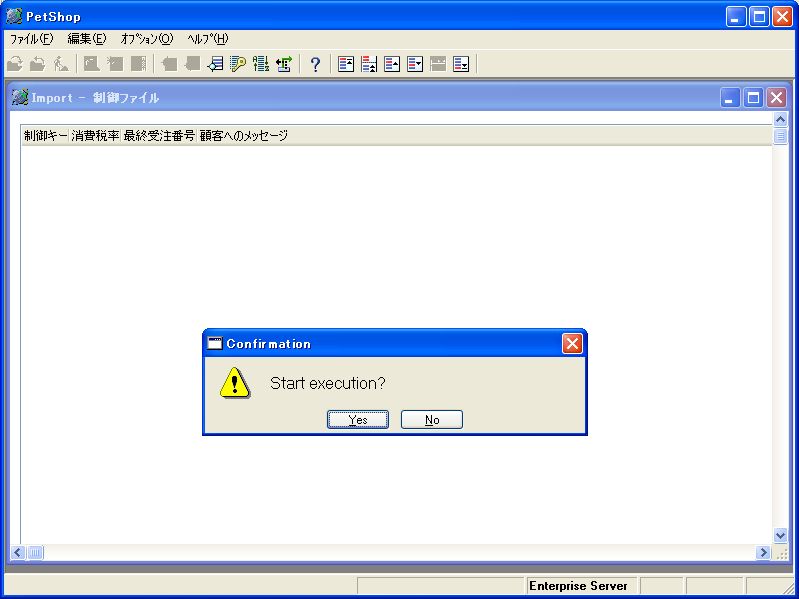
OKボタンを押すと、実行確認のメッセージが表示されます(画面8)。
- 画面 8 取り込み確認のメッセージ
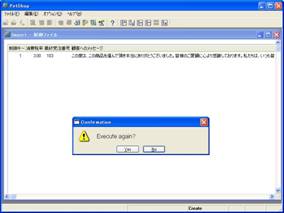
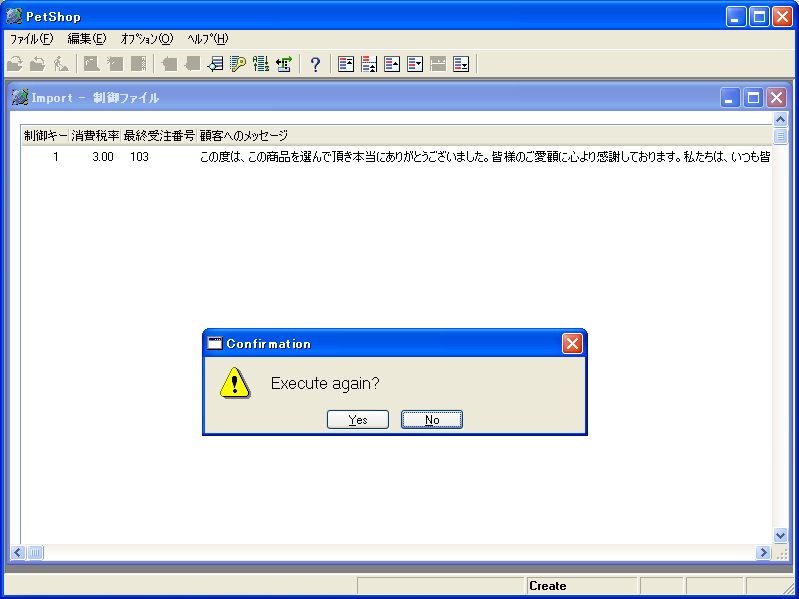
「はい」ボタンを押すと、テキストデータはほぼ一瞬で取り込みが完了し、再実行の確認メッセージが表示されます(画面9)。
- 画面 9 再実行確認のメッセージ
ここでは「いいえ」を押して、APGを終了します。画面はデータリポジトリの表示に戻ります(画面10)。
- 画面 10 APG完了の画面
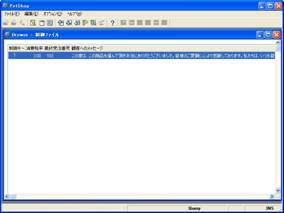
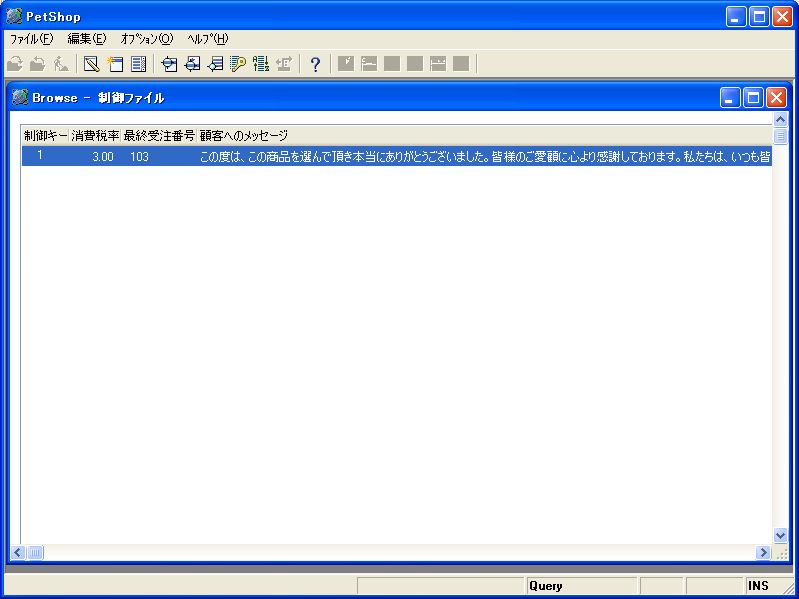
そして、ここでもう一度APGを起動し、今度は「モード」欄を「E=実行」、「オプション」欄を「B=照会」として、そのままOKボタンを押します。すると、APGで取り込まれたデータが正常に表示されることがわかります(画面11)。
- 画面 11 取り込みデータの確認表示
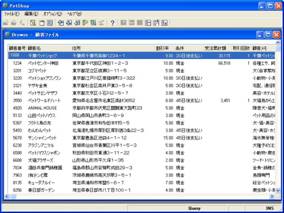
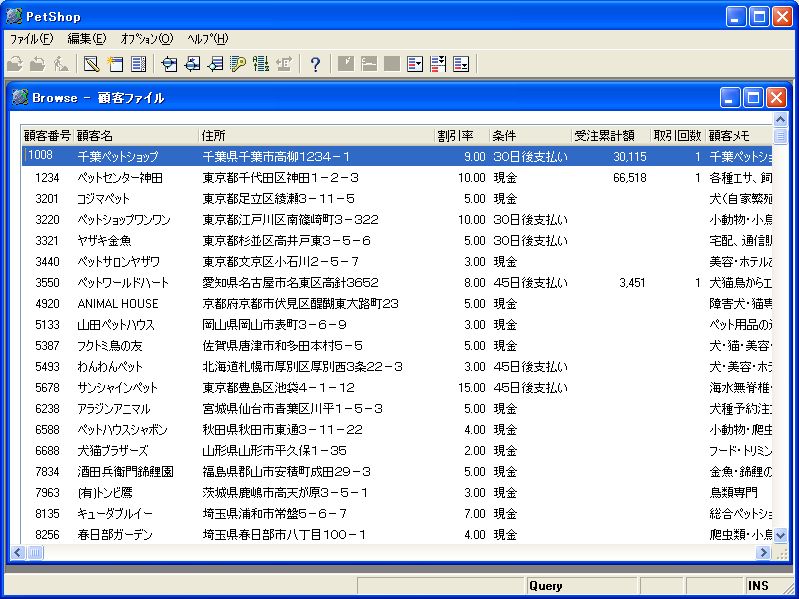
同様にして、顧客ファイル、商品ファイル、受注ファイル、および明細ファイルのテキストデータを取り込みます。取り込み後の各データソースのAPG表示は画面12~画面15のようになります。
- 画面 12 顧客ファイルデータの表示
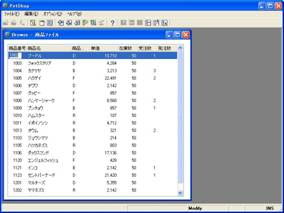
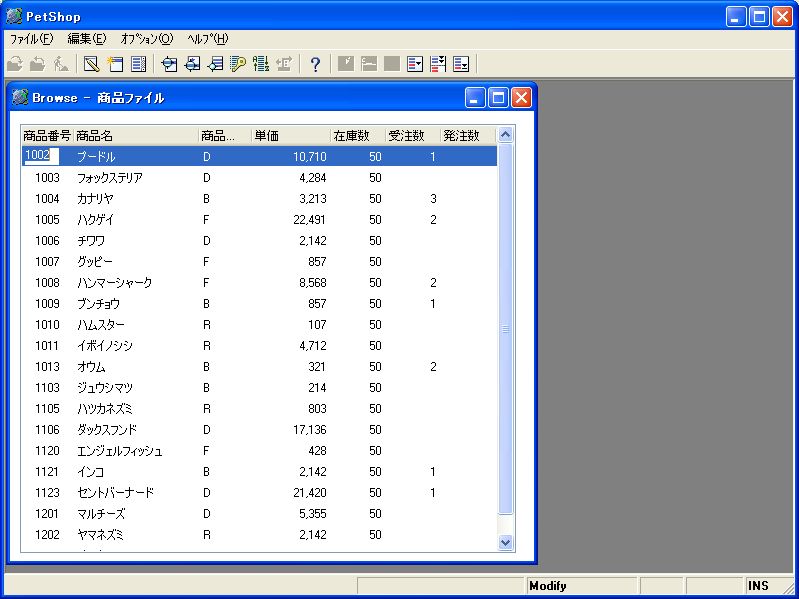
- 画面 13 商品ファイルデータの表示
- 画面 14 受注ファイルデータの表示
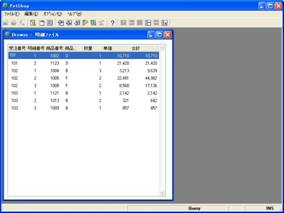
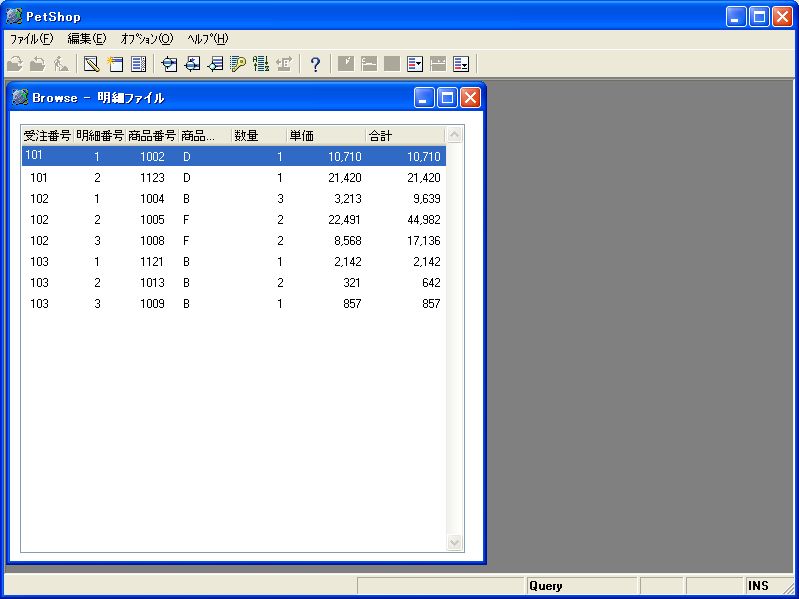
- 画面 15 明細ファイルデータの表示
ついでに、Unicodeデータの書式定義確認も行っておくことにしましょう。商品ファイルを使用して確認を行ないます。画面13の状態でCtrl+Mを押して、表示モードを「修正モード」に切り替えます(画面16)。
- 画面 16 商品ファイルデータの修正モード
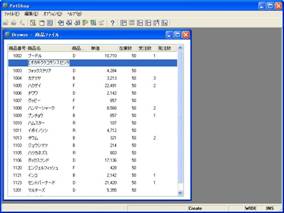
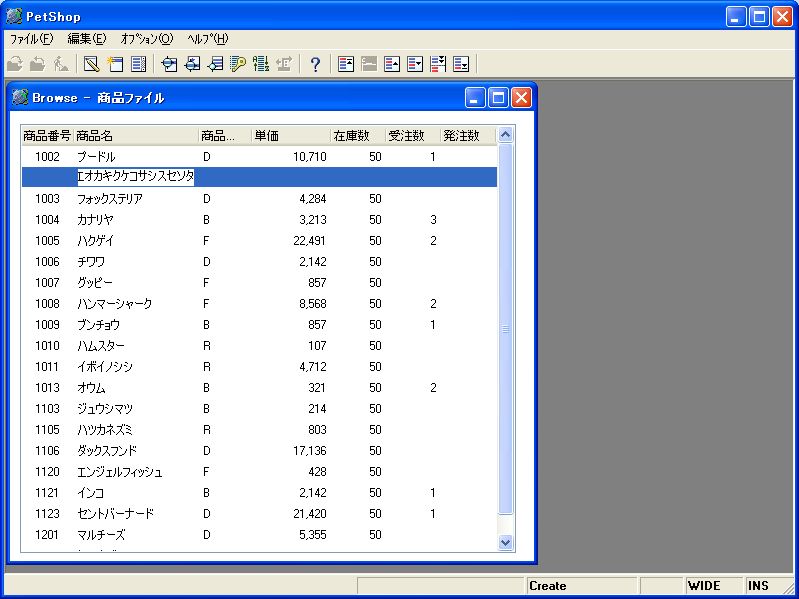
F4を押して新しい行を挿入し、「商品名」の欄に全角カタカナを16文字分入力してみます。ここでは、「アイウエオカキクケコサシスセソタ」と入力します。書式定義は16桁になっていますので、17桁目で入力がはねられることがわかります(画面17)。
- 画面 17 全角16文字以上の入力確認
では、今度は半角カタカナで16文字~17文字分入力してみましょう(画面18)。
- 画面 18 半角16文字以上の入力確認
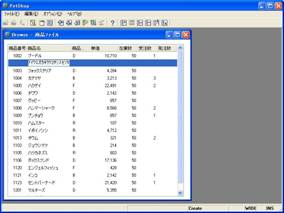
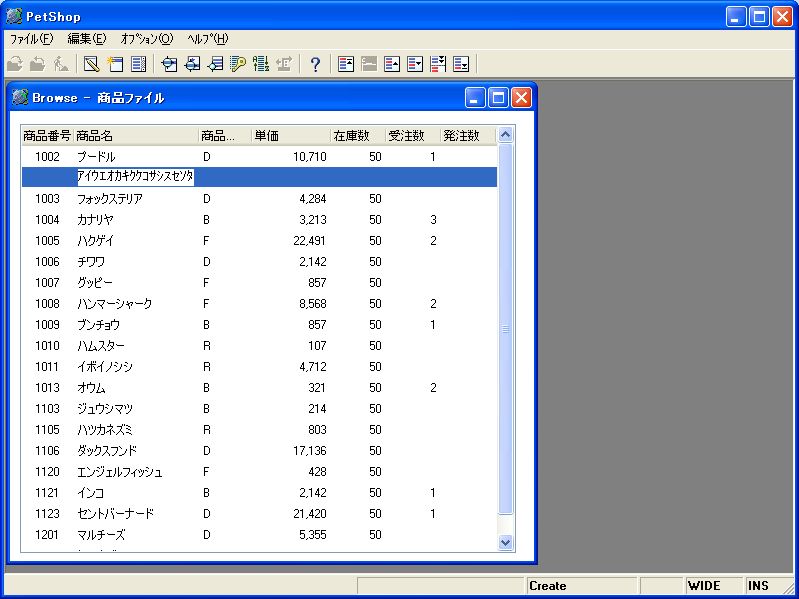
すると、こちらも半角文字であるにもかかわらず17文字目で入力がはねられることが確認できます。
以上が、Unicodeデータを用いる場合の、従来のANSI(Shift-JIS)との相違点です。特に、データリポジトリにおける自動変換作業時の桁数の取り扱いには充分な注意が必要です(※2)。
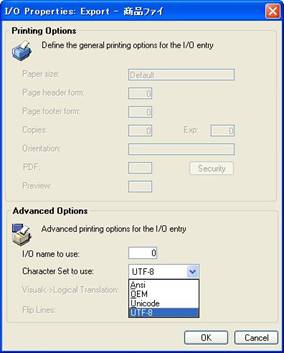
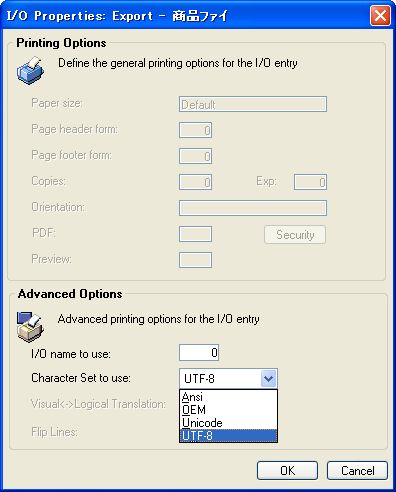
※2 入出力ファイルで使用する文字コードの設定は、プログラムリポジトリにプログラムとして登録すれば、入出力特性ダイアログで従来のANSI(Shift-JIS)などに変更することもできます(画面19)。
- 画面 19 使用する文字セットの変更
次回は、APGでリッチクライアントタスクを作成する手順について解説します。
(以上、2008年2月15日号)


